
Top AI & Tech News Today: Oxmiq’s $35M Raise, Nvidia’s Inference Push, and the Rise of Custom AI Silicon
The artificial intelligence industry is moving at breakneck speed. In just the past 48 hours, three major developments have highlighted where the future of AI is heading. From Oxmiq’s ambitious $35 million funding round to Nvidia’s aggressive inference strategy and the broader race toward custom silicon, the hardware side of AI is heating up faster than ever.
While most headlines focus on large language models and flashy AI applications, the real war is happening underneath: in compute infrastructure. Whoever controls efficient compute controls the future of AI.
The next decade of AI may not be won by the biggest model, but by the cheapest and fastest infrastructure.
1. Oxmiq Raises $35 Million to Build Unified AI Compute
Oxmiq has officially secured $35 million in new funding to build a next-generation AI chip architecture that combines CPU, GPU, and tensor processing into a single unified framework.
This is important because traditional AI systems rely on separate compute units, which creates latency, higher power consumption, and expensive integration costs.
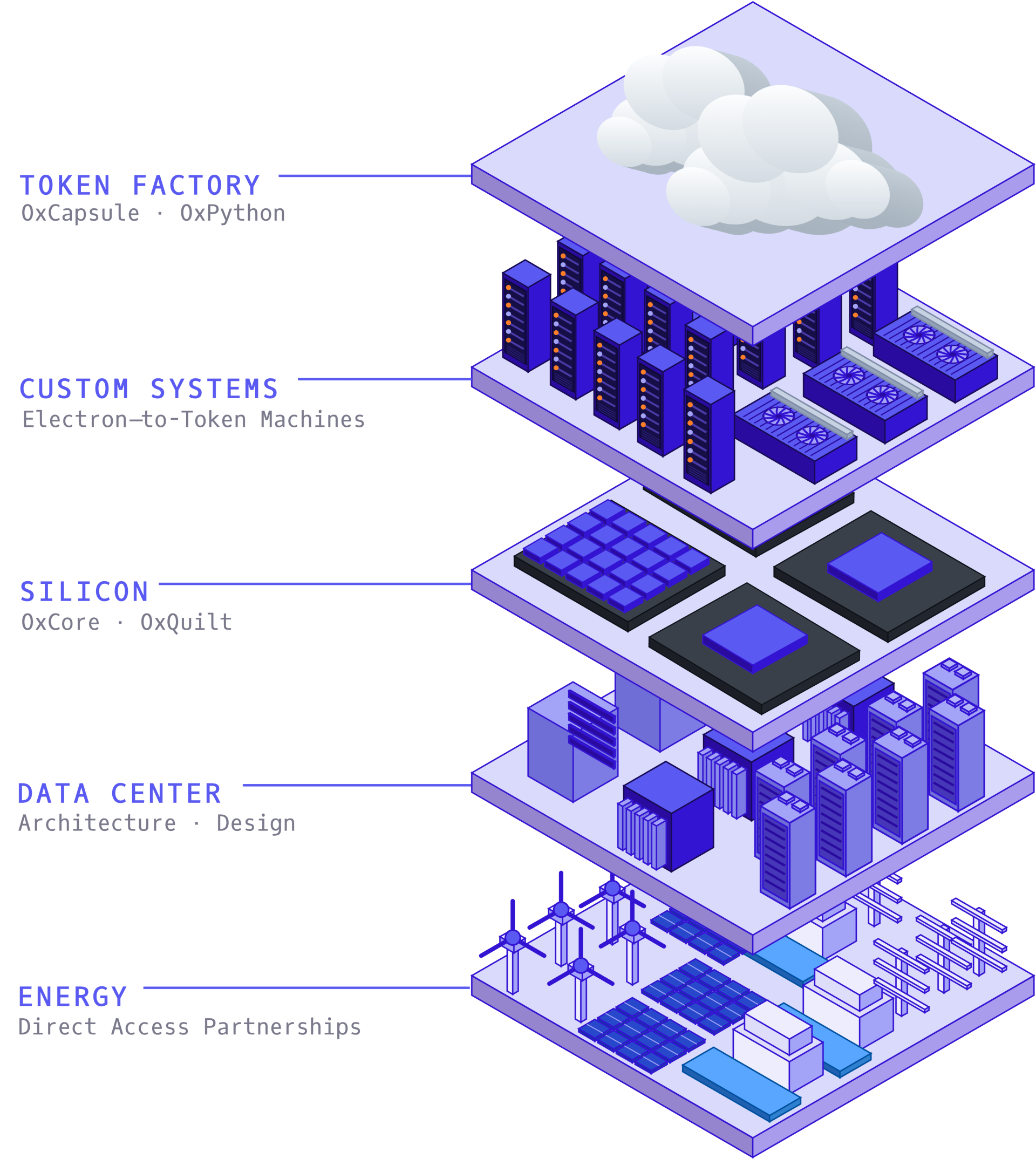
The company aims to license this architecture to hardware manufacturers, allowing them to build custom AI chips faster and more efficiently.
Why This Matters
- AI workloads are becoming more complex
- GPU demand is outpacing supply
- Inference costs are rising globally
- Energy efficiency is now critical
| Traditional Stack | Oxmiq Unified Stack |
|---|---|
| Separate CPU/GPU/Accelerator | Integrated compute model |
| Higher latency | Lower latency |
| More power usage | Optimized efficiency |
Industry analysts believe this could become a major turning point if Oxmiq executes properly.
2. Nvidia Doubles Down on AI Inference
Nvidia remains the dominant force in AI hardware, but its focus is shifting. Instead of only building training-optimized chips, Nvidia is now heavily prioritizing inference performance.
Why? Because inference has become the most expensive part of AI deployment.
Every AI chatbot message, image generation request, recommendation engine result, and code completion costs inference compute.
Inference vs Training
| Category | Training | Inference |
|---|---|---|
| Frequency | One-time | Continuous |
| Cost Pattern | High upfront | Ongoing |
| Scale | Limited | Massive |
This explains why Nvidia is optimizing memory bandwidth, token throughput, and latency.
The future of AI is serving billions of users efficiently.
3. Custom AI Silicon Is Becoming the Industry Standard
One of the strongest trends in 2026 is the rise of custom AI silicon.
Companies are no longer relying entirely on general-purpose GPUs. Instead, they’re designing specialized chips tailored for their exact AI workloads.

Examples include:
- Google TPU
- Amazon Trainium
- Groq LPUs
- Cerebras Wafer Scale Engine
- Oxmiq unified architecture
This trend is growing because specialized hardware can outperform general GPUs in specific tasks while consuming less power.
What This Means for Startups
For startups, this is massive.
Building AI products has been expensive because infrastructure costs scale quickly. But cheaper inference hardware could lower barriers dramatically.
- Lower server bills
- Faster product launches
- Higher margins
- More experimentation
Expert Analysis
We are entering the second phase of the AI boom.
Phase one was about building bigger models. Phase two is about making those models affordable and efficient at scale.
Infrastructure efficiency is now the real bottleneck of AI innovation.
This is why companies like Oxmiq matter more than they appear at first glance.
Future Predictions
1. AI Hardware Will Fragment
Expect more startups focused on niche AI hardware solutions.
2. Inference Will Become the Main Battlefield
Training gets headlines, but inference drives profits.
3. Edge AI Will Explode
Smaller, cheaper chips will bring AI to phones, robots, and local devices.
4. Sovereign AI Will Increase Demand
Countries want their own AI infrastructure, and custom silicon will help them build it.
Watch: Why AI Hardware Matters
FAQ
What is Oxmiq?
Oxmiq is a semiconductor startup building unified AI chip architecture.
Why is Nvidia focusing on inference?
Because inference is where AI companies spend the most money at scale.
What is custom silicon?
Custom silicon refers to specialized chips designed for specific AI workloads.
Will Nvidia lose dominance?
Not soon, but competition is increasing fast.
Why should startups care?
Cheaper AI compute means lower operating costs and faster growth.